Researchers develop a multi-modal vision-language model for generalizable annotation-free pathology localization
Nov 17, 2025
Accurate localization of pathologies in medical images is crucial for precise diagnosis and effective treatment. While deep learning has greatly advanced medical image analysis, most existing models depend heavily on large-scale manually annotated data. This reliance presents two major challenges: the annotation process is both costly and time-consuming, and models trained in a supervised manner often exhibit limited generalization in real-world clinical settings. Therefore, there is an urgent need to develop annotation-free deep learning approaches capable of generalizable, multi-modal pathology localization.
Recently, a research team led by Prof. WANG Shanshan from the Shenzhen Institutes of Advanced Technology of the Chinese Academy of Sciences, in collaboration with Prof. ZHANG Kang from the Wenzhou Medical University, developed a generalizable vision-language model for Annotation-Free pathology Loclization (AFLoc), which demonstrates superior performance in localizing pathologies and supporting diagnosis across a wide range of clinical scenarios.
The study was published in Nature Biomedical Engineering on January 6.
The AFLoc model integrates two encoders: an image encoder that extracts shallow local, deep local, and global visual representations, and a text encoder that captures word-level, sentence-level, and report-level semantic features from clinical reports. Through contrastive learning, AFLoc establishes multi-level semantic alignment between images and text, enabling language-guided image interpretation without manual annotations. This design allows the model to automatically learn the inherent relationships between disease descriptions and corresponding image regions, accurately highlighting lesion areas when provided with a clinical report or automatically generated text prompts.
The team evaluated AFLoc across three representative imaging modalities: chest X-rays, retinal fundus images, and histopathology images. For chest X-rays, the model was pre-trained on the MIMIC-CXR dataset and validated on eight widely used public datasets covering 34 common thoracic diseases, such as pneumonia, pleural effusion, and pneumothorax. Results showed that AFLoc achieved significantly better localization performance than existing methods and even surpassed human benchmarks in several disease categories. In retinal and histopathology tasks, AFLoc also demonstrated excellent lesion localization capability, with markedly improved precision compared with current state-of-the-art models.
In addition to lesion localization, AFLoc also demonstrated strong disease diagnostic capability. In zero-shot classification tasks across chest X-rays, retinal fundus images, and histopathology slides, the model consistently outperformed existing methods. Notably, in retinal disease diagnosis, AFLoc's zero-shot classification ability even surpassed some models that were fine-tuned with labeled data, highlighting its powerful feature representation capability.
"The goal of AFLoc is to reduce the dependency on manual annotations in medical image analysis. By integrating visual and linguistic semantics, the model learns directly from image-report pairs and demonstrates robust and generalizable performance across diverse imaging tasks. This study lays a foundation for developing scalable and efficient medical AI systems," said Prof. WANG.
This work develops AFLoc, a novel vision-language model that represents a promising step forward in medical image analysis by combining the strengths of multi-modal learning with annotation-free localization and diagnosis. Its strong performance across multiple modalities and its ability to assist in detecting both common and emerging diseases position it as a versatile tool with broad clinical applicability. With further refinements and integration into clinical workflows, AFLoc has the potential to improve medical diagnostics, providing healthcare professionals with AI-driven tools to enhance the accuracy and efficiency of patient care.
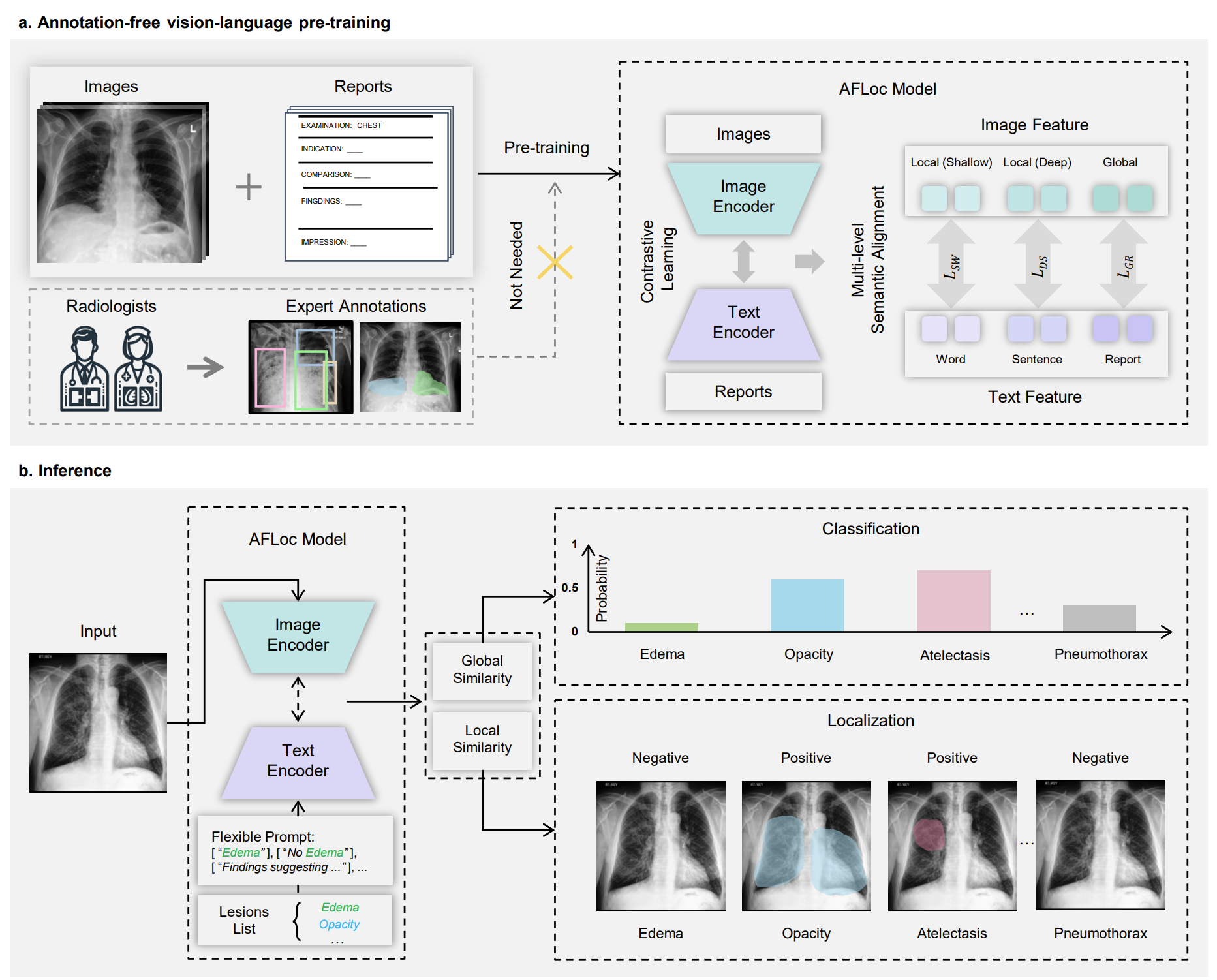
Schematic illustration of the multi-level semantic alignment during pre-training and the zero-shot inference pipeline of AFLoc. (Image by SIAT)
File Download:
Media Contact
YU Rong
Email:
rong.yu@siat.ac.cn
rong.yu@siat.ac.cn
More on this News Release
JOURNAL
Nature Biomedical Engineering
DOI
10.1038/s41586-025-09509-7
Related Articles
Nov 22, 2023
Experimental results showed that the proposed model achieves high performance with area under receiver operator curve all above 0.90 in classifying major tumor types, in identifying tumor grades wi...

Dec 22, 2023
The proposed methods are promising and open up new avenues for efficient cell analysis in various biological applications.